Recent post-training methods - particularly RL with verifiable rewards (RLVR) - have dramatically improved the reasoning capabilities of large language models. These approaches train models to produce a single, high-confidence answer, pushing them to commit to the most likely response at every turn.
This works well when there is one right answer. But real world data is messier than that.
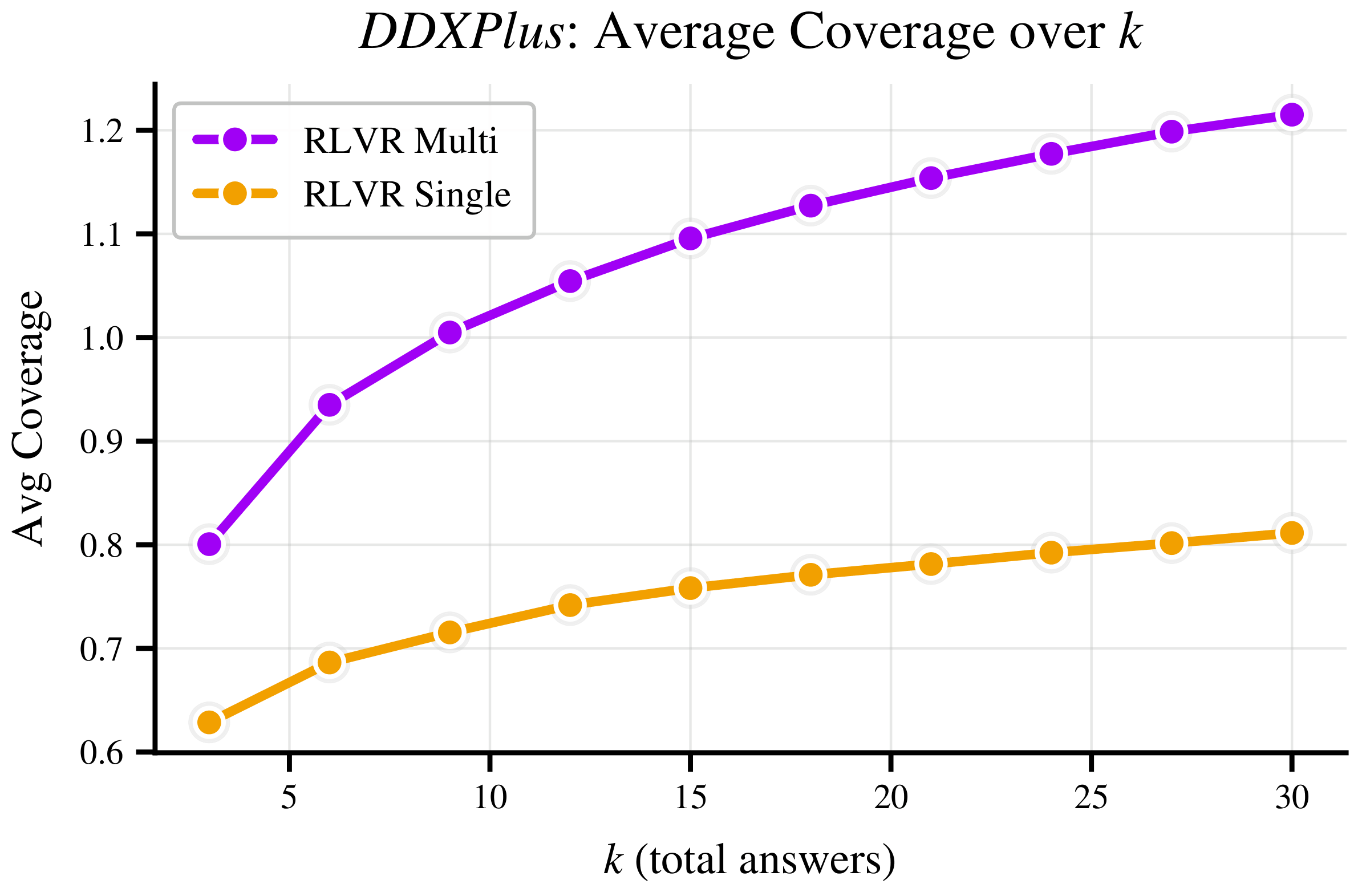
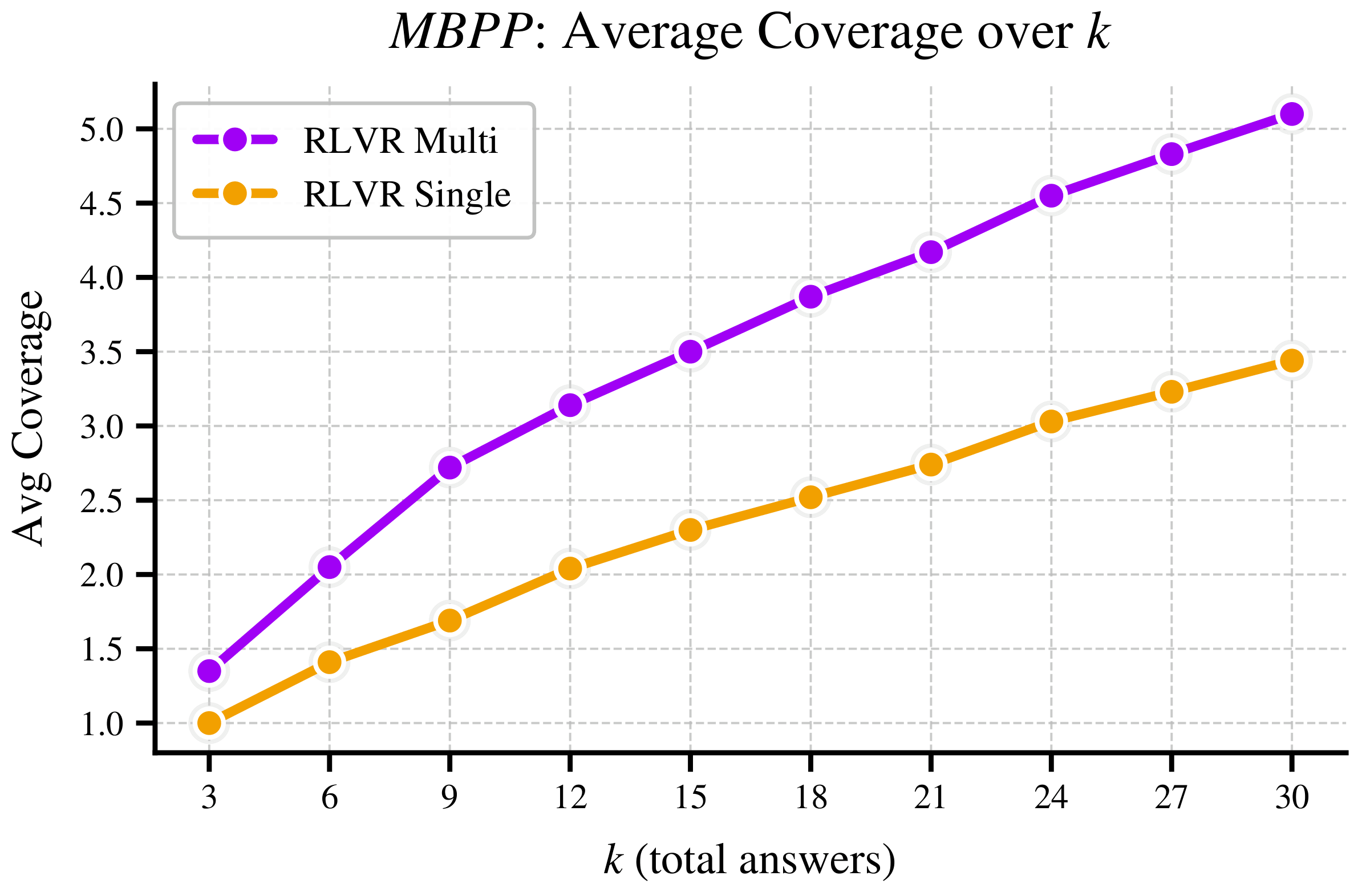
Consider a clinician seeing a patient with fever, hemoptysis, and chest pain. The right response isn't one diagnosis - it's a differential: a ranked set of plausible conditions, each with calibrated likelihood. Or consider a coding problem with multiple valid implementations, or a question where missing context leaves genuine ambiguity. In all these cases, the right output is a distribution over answers, not a single point estimate.
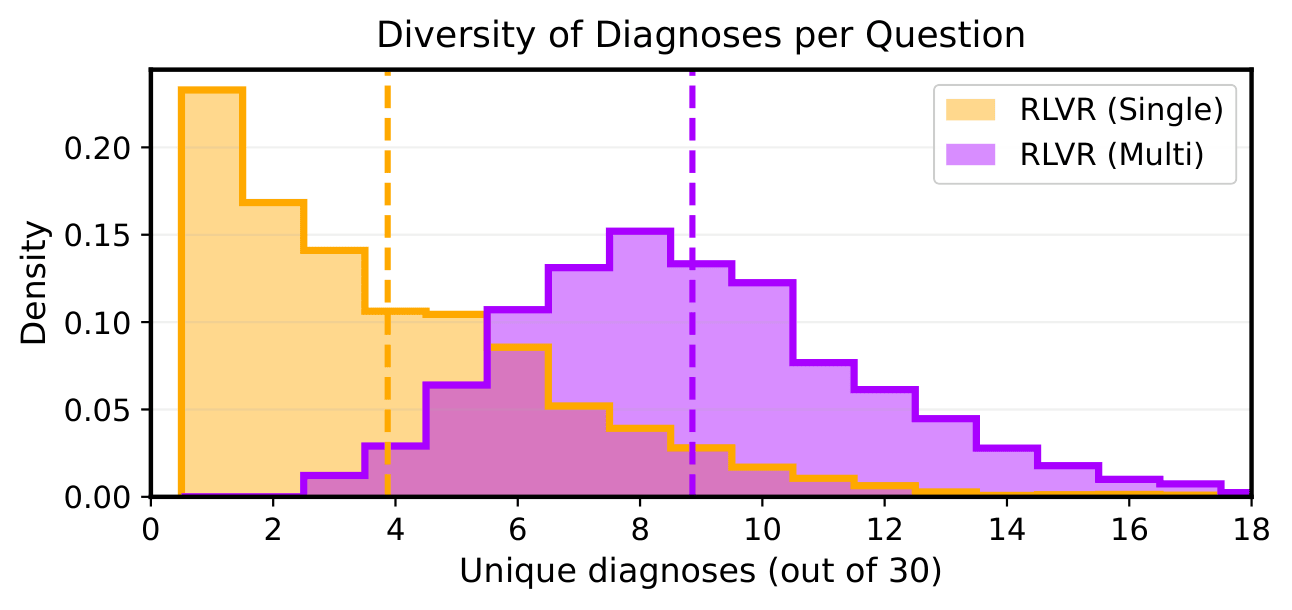
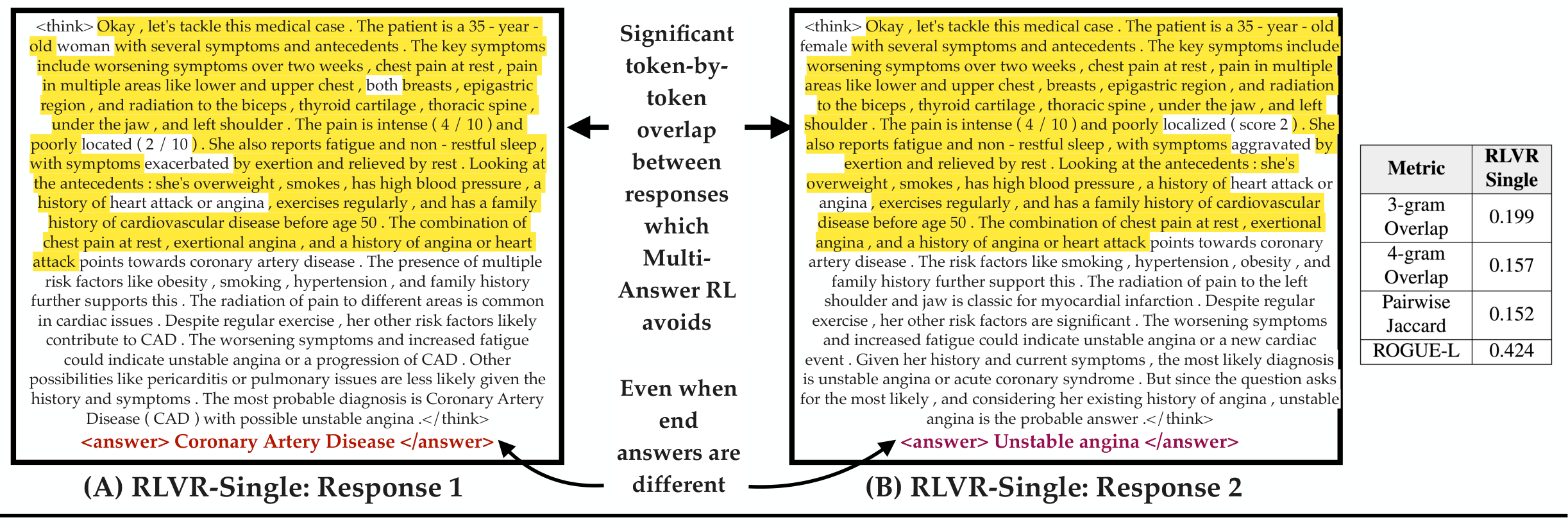
Standard RLVR is fundamentally mismatched to these settings. Because it rewards only the single highest-probability answer, models trained with RLVR suffer from mode collapse - they converge toward one dominant answer even when many valid alternatives exist, and they struggle to surface those alternatives even when sampled repeatedly.
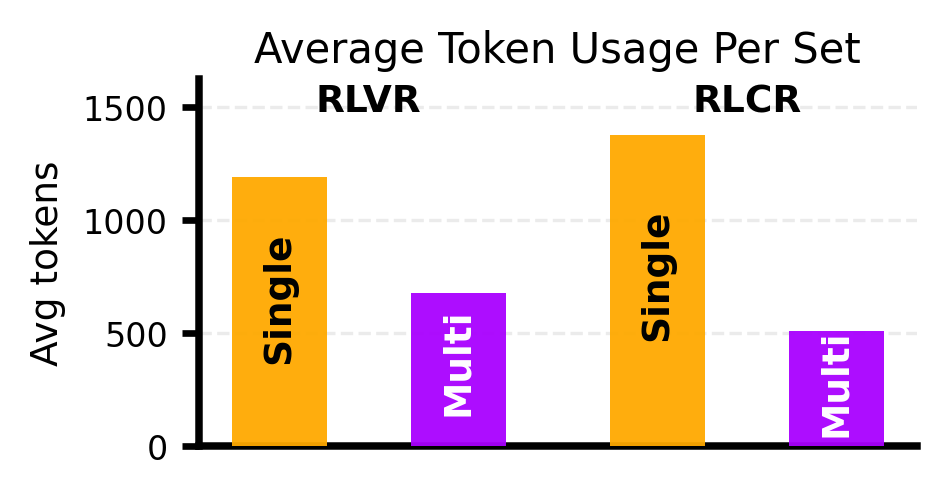
The naive fix - just sample the model multiple times - is both expensive and behaviorally misaligned. A model trained to commit to one answer will regenerate the same reasoning scaffold over and over, wasting compute and missing valid alternatives.
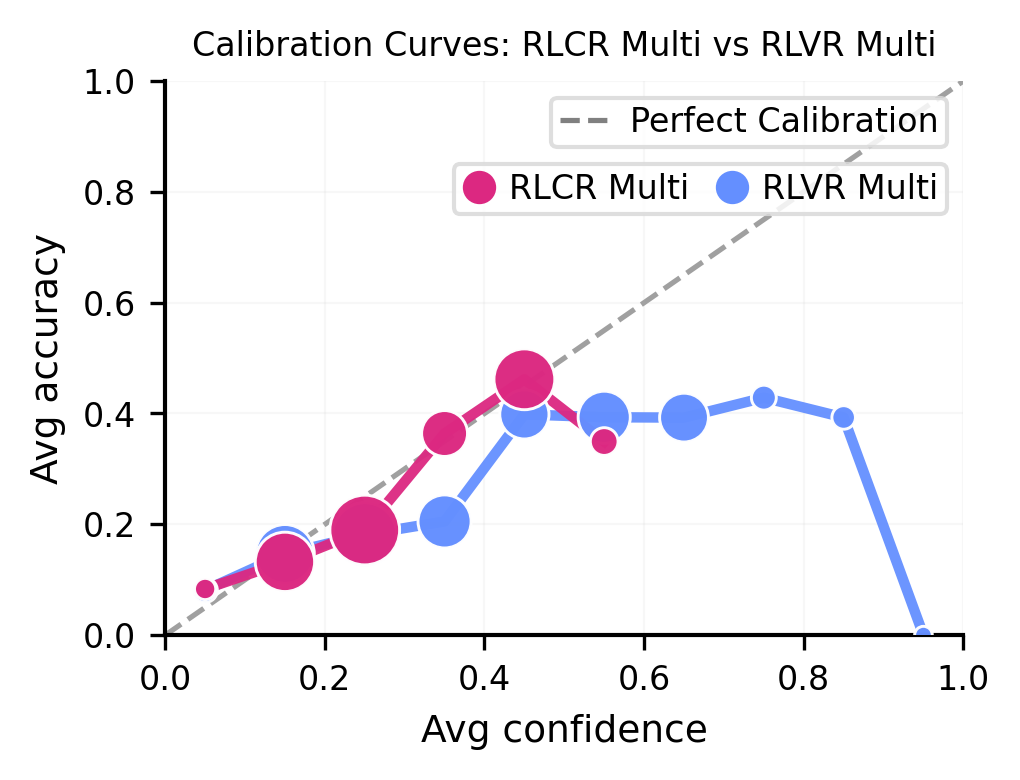
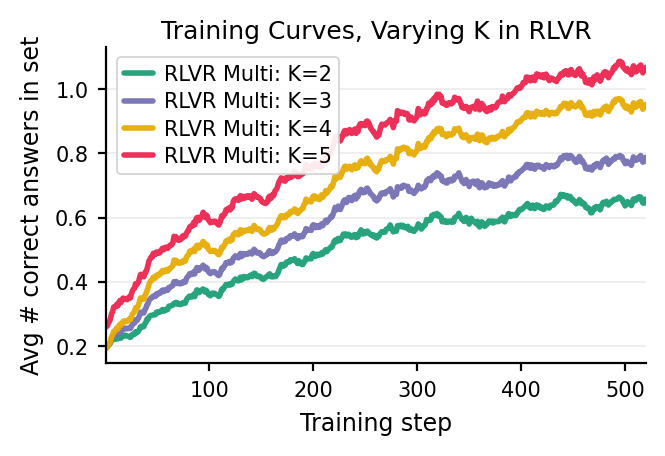
We introduce Multi-Answer RL, a training framework that directly optimizes language models to generate sets of diverse, calibrated answers in a single forward pass - reasoning jointly over multiple hypotheses rather than collapsing to one. The result is a model that is more accurate ✅, more diverse 🎲, better calibrated 🎯, and more compute-efficient 🚀 - all at once.